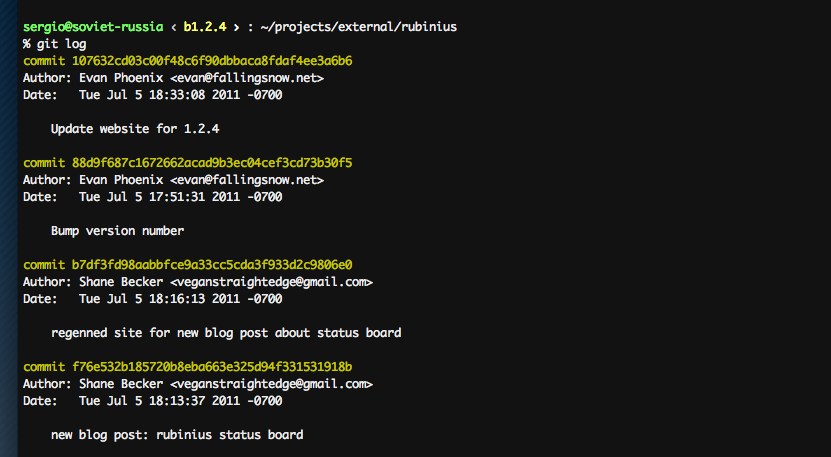
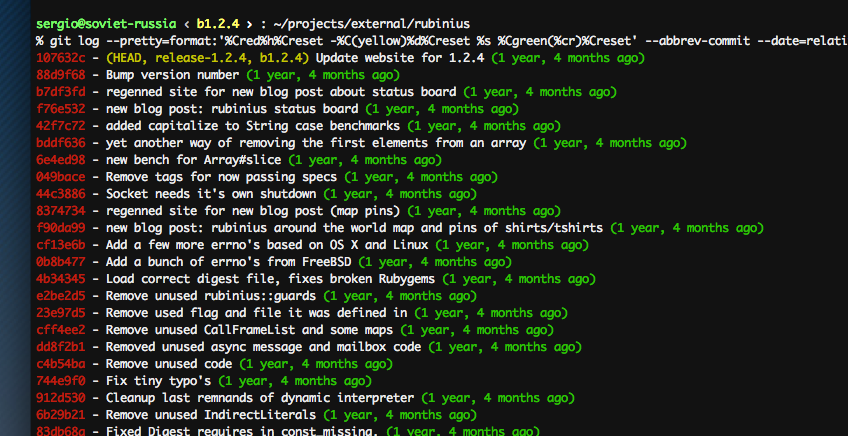
While it is sure contains the information and is easily parsable by a machine, it’s
not the best way to present it to a human. Luckily, the git log commands is quite
customizable. Try this, for example:
Oh, the TextMate 2 we all waited for so long. Okay, I wasn’t really waiting,
but I kept hearing about it. Never got to install the app.
So, tonight I wasn’t able to fall asleep. I opened my macbook and started reading
news. One thing led to another and the next thing I know, I’m installing alpha
version of TextMate and a bundle for Go. Really, Go? I hope
I won’t be too surprised tomorrow :)
Okay, what’s new?
If you open a file with unknown extension, TextMate will offer to install a
bundle for it, if there’s one.
“Right margin” is now called “View -> Show Wrap Column”
You can specify a default language for new files. 90% of my new files are Ruby
scripts, so it is a timesaver for me.
New file browser. I’m not sure if I like it better or not.
When you click on items in the file browser, they don’t open automatically. You have to double-click.
Awesome new app icon! :)
I will update this post when I find something new.
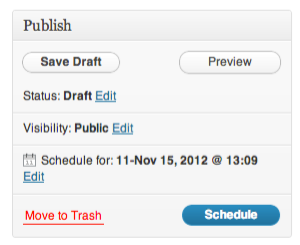
One of the powerful things that Wordpress can do and Octopress can’t, is deferred posting
(or scheduled blogging, whatever). I never really missed it when I was using Wordpress, so
I switched to Octopress without hesitation. But now I could use that feature. In case you
don’t know, deferred posting allows you to write a post beforehand and schedule its release
to some moment in future.
This functionality is kinda trivial if you use dynamic request processing and a database
(like wordpress does). But with static sites it’s not at all that easy. So before
implementing something myself, I decided to google for other works on this topic. Here’s
a good article that I’ve found: Synced and scheduled blogging with Octopress.
It also contains some links to other articles.
In short, people write a daemon (or scheduled script) that checks your drafts from time to
time. If a draft is due, it is copied to _posts directory and generate/deploy sequence
is initiated.
This, obviously, requires a computer that is always on and has actual content for the site.
I don’t really like the idea of a daemon, but, I guess, this is a price you pay for using
“blog engine for hackers”.
Could this be implemented as an external web service? Is there an opportunity for a
profitable startup? :)
After having worked with MongoDB for a while, I really miss its dynamic features when
dealing with “legacy” systems (MySQL, in this instance). How cool it would be to just start
inserting data into random collection and it will magically appear in the DB? Good news is:
it can be done.
Method lookup is an interesting topic in Ruby. For example, exactly what happens that
produces this output from this code?
123456789101112131415161718192021
moduleFoodefhellosuperifdefined?superputs"foo"endendclassBarincludeFoodefhellosuperifdefined?superputs'bar'endendbar=Bar.newbar.hello# >> foo# >> bar
The algorithm for method lookups can be summarized in one sentence: “one step to the right,
then up”. This is referring a specific visualization of objects and classes relationships,
where we place object’s class to the right from the object, and place ancestor of a class
above it.
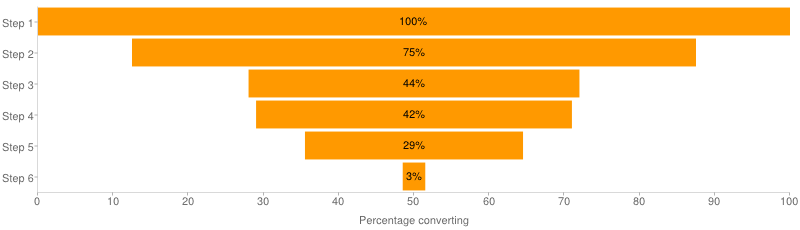
Recently I came across this excellent way of visualizing a funnel. It’s simple, informative
and it doesn’t look like a freaking funnel (with neck and all).
The only negative property of it is that it’s implemented with Google Charts API. Sure,
it’s free and pretty, but it’s also an external service call and a dependency. Today I’ll
show you how to make this kind of charts yourself in your charting library (I’ll be using
highcharts.js).
Still driven by that post,
I decided to do something about it. So I went and tried to read the original paper. It was
mind blowing. Not because it was great (I am sure it is), but because it’s been a while
since I had to read some serious math.
Then I came across this article, which could also be named “HyperLogLog for dummies”:
Fast, Cheap, and 98% Right: Cardinality Estimation for Big Data.
It was much more readable. From it I learned about Murmur hash and was surprised that
there’s no ruby gem for this. Fortunately, C++ source code
was available, so I decided to wrap this as a gem.
It went much smoother than I anticipated and I had working version within 3 or 4 hours.
I didn’t have experience with native extensions before, someone experienced probably could
have done it in 5 minutes, but still I consider this as an achievement! :)
So, only when I tried to push the gem to RubyGems, I discovered that there IS
a gem with this name: murmurhash3. The public API
is too cumbersome if you ask me, but it works and probably has less bugs than my version.
Here’s how you use it:
12345678
require'murmurhash3's="Hello, world!"ints=MurmurHash3::Native128.murmur3_128_str_hashs# produce a 128 bits of hash, in the form of 4 32-bit integersints# => [3537266143, 4048629201, 2834548068, 741500496]
You can turn this array of integers into a hex string like this:
One nice application of set sketches is efficient storage and retrieval of analytics-type data: if you want to count the number of distinct users who have performed specific actions in your system (“visited page X”, “pressed button Y”, “followed user Z”, etc.) you’re quickly overwhelmed with the amount of memory needed to store even bit vectors representing all events for all users. Bloom counters are sometimes used for this sort of thing, but they still require a significant investment in space and the results of individual counters can’t be easily/efficiently combined.
HyperLogLog is a good alternative when you don’t need exact counts: with a small, fixed amount of space per counter, it can yield good estimates of set cardinality - usually to within 2% of the actual count. In addition, the counters can be combined and queried at little extra cost, so that you can compute estimates to queries like “how many users visited page X and pressed button Y” or “how many users follow either user W or user Z” in real time. All of the operations take O(1) time and space in the cardinality of the sets being represented. Adding an element to a set sketch is particularly fast, essentially just the cost of applying a hash function to the element.
Now that I know about this technology, I desperately want it. I could really use that
because my current app has a lot of sets, and some of them can get pretty large. Being
able to use constant size is a huge relief, because you can correctly estimate amount of
memory taken by Redis. And being able to combine them (UNION/INTER) is priceless.
The only thing that is not clear to me is how this will play along with upcoming Redis Cluster.
Single key operations are OK, of course, but what about multiple key ops?
I really hope that Salvatore will not reject this functionality :)
I was using resque-multi-job-forks
plugin for quite a some time. What was bugging me is that the project seemed to be abandoned.
There were no new commits for 2 years. And current version of the gem had dependency on an
archaic version of Resque. So, I forked, bumped the dependency and bundled the gem. But
then I thought: “Hey, why not share it with people?” I exchanged a couple of emails with
the owner and now I am the official owner/maintainer of said gem. This is my first
takeover, hooray! :)
To celebrate this, today I have released version v0.3.2, which includes updated resque
dependency and fix for the problem when workers disappeared from resque-web after the first
fork has reached its limit.
Okay, I probably can’t avoid writing the obligatory migration article :) If in the
migration process you decided to also change the domain name, then this article is for you.
If your domain name is the same, only the hosting is different, then you should set up a
CNAME. If you wiped Wordpress and installed
Octopress in its stead, then this article is useless to you, move on.