I must admit, I didn’t really understand what Unicode (more specifically, its flavor “UTF-8”) actually is. All I knew was that it’s a good encoding and it’s compatible with ASCII. Beyond that - no clue. This video has made it crystal clear.
Pipeline Processing in Go
Pipeline processing is a very powerful design idiom. You have some simple building blocks that you can arrange in different combinations to perform complex tasks. A classic example of that is unix command line. Each tool is very simple. It does only job. But it still amazes me regularly, what you can achieve by simply combining those tools into a pipeline and feeding/piping data through it.
Say, you’re building an RSS reader that shows new posts live. Implementing it in a regular procedural manner is easy. Something like this (pseudo-code):
loop {
fetch posts
for each post {
if we have not yet seen this post {
mark post seen
show it to user
}
}
}
Say, now we want to do a focused reading. Which means that we only want to see a subset of posts which satisfy some arbitrary criteria (filter by tags, etc.). No problemo, we just add one conditional in there.
loop {
fetch posts
for each post {
if post is interesting {
if we have not yet seen this post {
mark post seen
show it to user
}
}
}
}
Now it’s getting a little bit difficult to read and it will get worse. All business rules are in the same pile of code and it may be difficult to tell them apart.
But if you think about it, there is a pipeline that consists of several primitive segments:
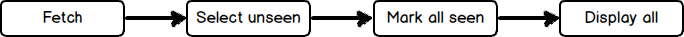
Each individual block is completely separate from each other (well, maybe except that “select unseen” and “mark all seen” might use the same storage). If we were to, say, remove caching (and stop serving cached content), we’d only have to take out those two segments. If we want to change how content is presented to user (print to terminal, send to text-to-speect engine, …), we only have to replace the final segment. The rest of the pipeline stays untouched. And the aforementioned tag filtering - we just insert it after fetcher:

In the pipeline, each segment can either swallow a message or pass it on (after applying some transformation (optional)). Two simple rules, infinite flexibility.
Go language allows for natural expression of this design: goroutines as segments, connected by channels.
Here’s an intentionally primitive example, which filters and transforms a stream of integers.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 | |
Produced output:
Resulting value: 5 Resulting value: 17 Resulting value: 37 Resulting value: 65 Resulting value: 101 Resulting value: 145 Resulting value: 197 ...
First generated integer is 0. It’s even (well, certainly not odd), so it does not make it past filter.
Next one is 1. It passes filter. Then it gets +1, so it’s now 2. Then it’s squared and becomes 4. And finally, one more +1 which results in 5. There are no more segments, so this value is read from the output pipe and printed to terminal.
Hope this was useful.
Hide/exclude Directories in TextMate 2
I decided to give TextMate 2 another try today. Hopefully it won’t freeze upon trying to install a bundle like it did last time. Now I don’t recall which bundle was that, but so far things are going well. Mostly.
When I opened my Rails app and tried to navigate to file (Cmd+T), I saw this:
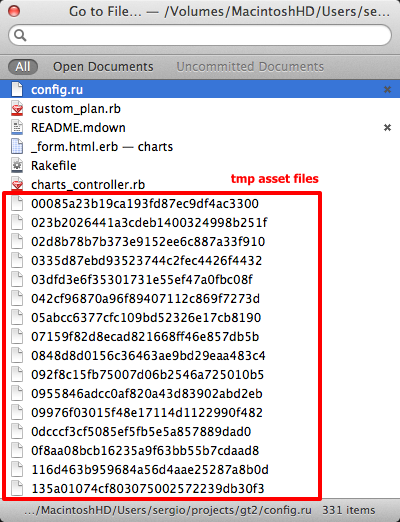
At first I thought that these are files from .git folder and spent embarrassing amount of time trying to make TM2 hide that folder. But these are actually temp asset files generated by Sprockets and they reside in tmp/assets/....
Long story short, here’s how you can hide a directory in TextMate 2, both from project browser and navigation dialog.
Create a .tm_properties file. It can be in current project dir or any parent dir (up to $HOME). Put this line into it.
1
| |
It is worth noting that "{tmp}" doesn’t work. Apparently, TextMate glob parser breaks down if it can’t find a comma. So we add one. Alternatively we can use this line:
1
| |
It will amend an existing excludeDirectories setting (empty string by default) instead of replacing. And it also has a comma. :)
Hope this post saved you some time.
Move Capistrano’s Log Directory
So you want to move your log directory? To a separate volume, maybe? But you are afraid that it will break too many things, like all those libraries with #{rails_root}/log paths hardcoded in them? Fear not, there’s a simple workaround.
As you probably know, capistrano aliases your rails log dir to a shared dir outside of app folder.
1
| |
This means that, in fact, all your logs turn up at /deploy_path/shared/log/. Now all we need is to symlink that dir as well!
1 2 3 4 5 6 7 8 9 | |
Hope this helps :)
Cap Deploy From an Arbitrary Branch
As you know, capistrano can deploy your app from a specific branch in the repo. You just have to specify it
1
| |
If you develop in a single branch, that should do it for you. All commits go to one branch and all deploys are likely served by the same branch. This is a simple model, good enough for small projects.
However, if you adopt git flow, it encourages you (not to say “forces”) to have separate branch for every feature, release or hotfix that you’re working on. And, naturally, you want to deploy to dev/staging server right from a feature branch, not having to merge it first to develop/master. This is trivial to accomplish, just change the branch name:
1
| |
Now you have a pending file change. What do you do with it? Commit to source control? That increases file churn rate for absolutely no reason. git checkout that file? This is an extra action, of which you will be tired quite soon (not to mention chance to accidentally commit the file).
Solution? Externalize the setting. When deploying, look in the environment for a branch to use and fallback to default name.
1
| |
Then you do this
1
| |
Or, if you have multistage enabled
1
| |
Of course, this requires a bit more typing on each deploy, but at the same time it decreases chances of deploying from a wrong branch.
Happy deploying!
Sorting Humanized Numbers in tablesorter.js
Tablesorter is a jQuery plugin for sorting tables. It appeared first in a couple of “X jquery table sorting plugins” blog posts, so I went with it when I needed to sort a table a couple of days ago.
It works pretty well out of the box and it even lets you customize some bits. One of those bits is column parser: if you have special data in a column, you need a special way to sort it.
Here’s an official example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
However, it leaves much to be desired. Like what to do when I want my parser to be auto-detected. Turns out that this is function is a predicate. It accepts a string and decides whether it can be handled by this parser. Then the format function will make conversion to a normalized textual/numeric form.
In my case I have a table with a lot of numbers. And those numbers are in humanized form. That is, instead of 121738 I output 121.74k. This format is not properly sortable as either number or text, so I wrote a parser.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
It basically checks if a string consists of a number followed by an optional “M” or “k” and, if that’s the case, converts it to a “full” number.
I wish this was in the official doc.
Queue Prioritization in Sidekiq
Unlike Resque, Sidekiq allows you to process several queues at the same time. You can even assign priorities. Here’s an example from default config:
1 2 3 4 | |
If you want two queues have equal rights, just set the same priorities. However, if you omit priority parameter and define your queues like this:
1 2 3 4 | |
Then queues will be checked in a serial manner. That is, Sidekiq will start making coffee only when all emails are sent. If a new email shows up, it will be processed before any other job. In other words, this is how Resque would handle the queues.
Choose whatever fits your task better. It’s nice to have some flexibility.
Using Sidekiq With Redis_failover Gem
Sidekiq works pretty well with standard redis client. This is an example of configuring it (from official wiki):
1 2 3 4 5 6 7 8 | |
But, what if you need a special redis client that can’t be initialized with redis URL? No worries. Setter for Sidekiq#redis also accepts a ConnectionPool. Here we have full control over how we initialize our redis client. Here’s how you may initialize Sidekiq with a bunch of RedisFailover clients:
1 2 3 4 5 6 7 8 9 10 | |
You can even read Sidekiq’s concurrency setting and pass it to the connection pool initializer. Now your sidekiq farm doesn’t care about redis crashes :)
Happy sidekiqing :)
My (Un)success Story of Colemak
I’ve been hearing a lot about Colemak recently. It’s a (relatively) new keyboard layout, specially designed for efficient touch typing in English. Any description
of Colemak (including this very post) is accompanied by a story, how QWERTY layout was specifically designed to hinder fast typing, so that typewriter bars don’t get stuck. Ok, cool story, let’s try this silver bullet layout.
One of the advertised advantages of this layout is that “most” common QWERTY hotkeys are the same. Indeed, such hotkeys as select-all/cut/copy/paste didn’t move. Yes, this is an advantage for people who copy/paste text all day. But for us, coders, this is really a disadvantage, because some hotkeys are on the same keys, and others have moved. And worst of all, most hotkeys have changed their meaning.
Let me illustrate. Most (all?) browsers in Mac OSX understands the same hotkeys:
- Cmd-T - open new tab
- Cmd-F - find
- Cmd-G - find next
- Cmd-S - save
We’ve been using these hotkeys for years and now they are burned in our muscle memory. So, with Colemak, when you try to perform an action and you reach for the old key, you get completely different action instead.
- You tried Cmd-T (qwerty), you hit Cmd-G (colemak), action - “find next”
- Cmd-F, Cmd-E, “use selection for find” (chrome)
- Cmd-G, Cmd-D, “add bookmark”
- Cmd-S, Cmd-R, “reload”
This is very, VERY frustrating to try search page content and keep adding bookmarks instead. Combine this with a fact that when you switch to a Russian layout, the hotkeys are the same as in QWERTY. So, essentially, you have to learn a whole new set of hotkeys for every program you use and always keep track of the current layout, or otherwise you’ll get unexpected results.
Now, is it really worth it? Given the fact that programmer’s productivity is not based on how fast and for how long he can type, I’d say “Not really”. I average 370-450 CPM on QWERTY. This is far more than sufficient for everyday coding needs.
Goodbye, Colemak. Hello again, QWERTY.
Talking Capistrano Is Your Friend
I want to share with you a small tweak I came up with a couple of days ago. As some of you
know, Mac OS X includes a ton of very handy utilities. One of them is say. The name is
pretty descriptive, you pass it a string and it voices it, using text-to-speech engine,
that is built in Mac OS. Try it now:
1
| |
You can use it anywhere where you can invoke shell commands. Here’s my capistrano after-hook, for example:
1 2 3 4 5 | |
Now I can launch my cap deploy (which can take minute or two) and go read Hacker News or
whatever. I will be told when deploy is finished. I’m using this for a few days already
and it still make me smile everytime. I should probably come up with more creative messages.
Happy tweaking!